
Inilabas ng Qwen team ng Alibaba ang Qwen-Robot Suite noong Martes: tatlong pangunahing modelo na bumubuo sa tinatawag nilang "full stack para sa embodied intelligence." Ang Qwen-RobotNav ang humahawak sa mobility. Ang Qwen-RobotManip ang humahawak sa manipulasyon. Ang Qwen-RobotWorld ang nagsisilbing simulator ng physics na nagpapahintulot sa dalawa. Ang bawat isa ay gumagana nang hiwalay. Kung pagsasamahin, sila ang Android moment para sa robotics—ang operating system, hindi ang hardware.
📣 Introducing the Qwen-Robot Suite — Qwen-RobotNav, Qwen-RobotManip, Qwen-RobotWorld, three foundation models, a full stack for embodied intelligence.
🧭 Qwen-RobotNav — the gateway to mobility.
• Unifies 5 navigation tasks in one model: instruction following, point-goal,… pic.twitter.com/noumjTtTeS— Qwen (@Alibaba_Qwen) June 16, 2026
Ang Alibaba sa kasalukuyan ang tanging kumpanya sa China na sumasaklaw sa chips, cloud, modelo, serving platforms, at mga aplikasyon. Para sa kumpanya, ang robotics ang pinakapisikal na ekspresyon ng pusta na iyon, ang tinatawag na embodied AI.
Ang mga ahente ng AI ay kasalukuyang umaasa sa mga LLM upang paganahin ang kanilang mga desisyon. Ang karaniwang paraan ng paggana ng mga robot ay sa pamamagitan ng mga modelo ng machine-learning na, bagama't advanced, ay walang kakayahang umangkop ng generative AI. Ang mga pisikal na ahente ay humaharap sa isang iba, mas mahirap na klase ng failure modes: physics, hindi prompts.
Para sa mga use cases na ito, ipinakilala ng Alibaba ang bagong AI suite na ito na may iba't ibang bahagi:
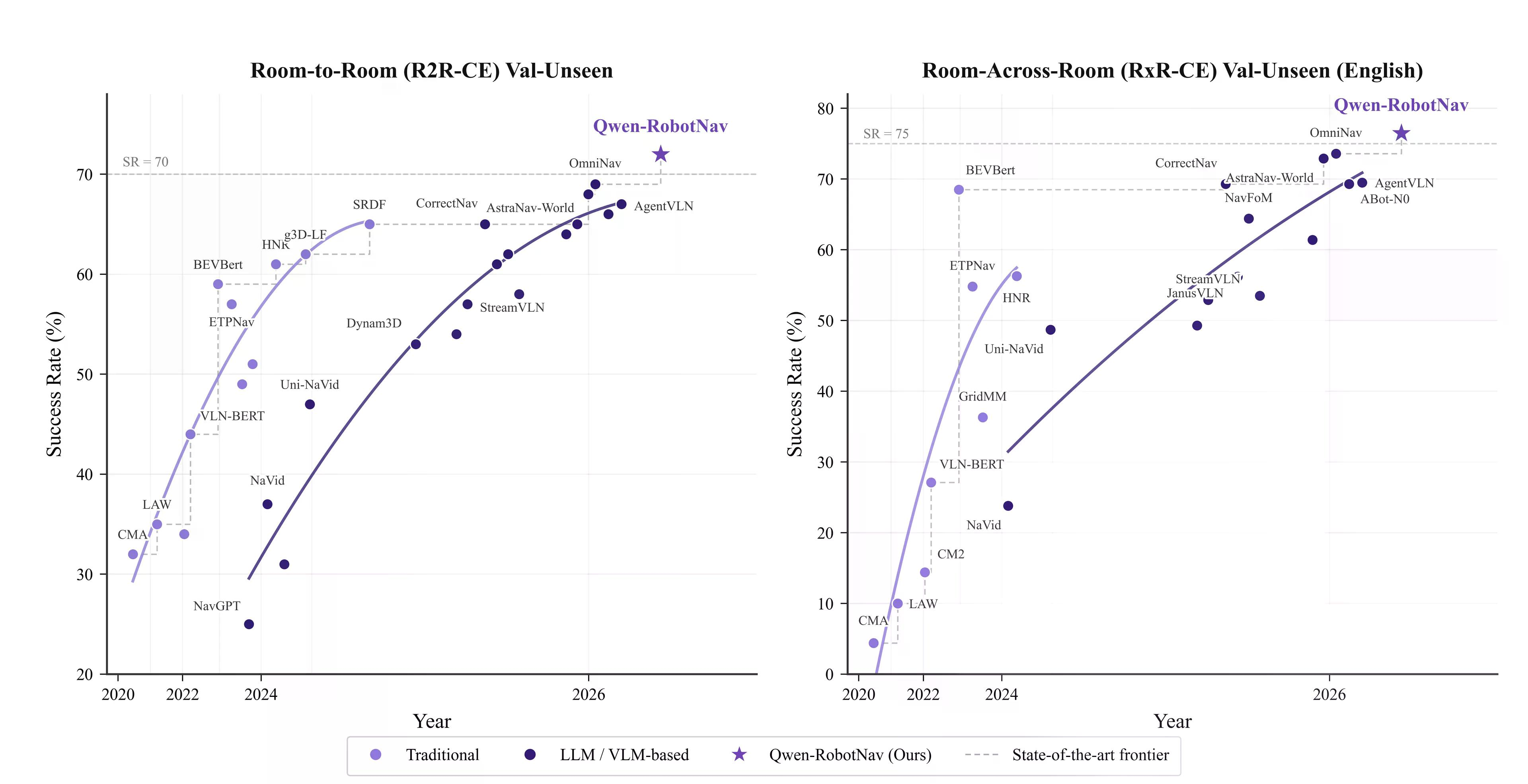
Pinag-iisa ng Qwen-RobotNav ang limang navigation tasks—instruction following, point-goal navigation, object search, target tracking, at autonomous driving—bawat isa ay nangangailangan ng iba't ibang visual memory strategies. Karamihan sa mga modelo ay hardcoded ng isang strategy. Ang Qwen-RobotNav ay naglalantad ng isang parameterized interface: token budget, temporal decay, per-camera weights na maaaring i-reconfigure ng isang planner sa kalagitnaan ng episode.
Sinanay sa 15.6 milyong sample na may randomization sa lahat ng parameter, nakakamit nito ang 76.5% na tagumpay sa VLN-CE RxR, isang benchmark para sa vision-and-language navigation sa real-world environment, at 90% tracking sa EVT-Bench, na sumusuri sa kakayahan ng isang ahente na tuloy-tuloy na sundan ang gumagalaw na target.
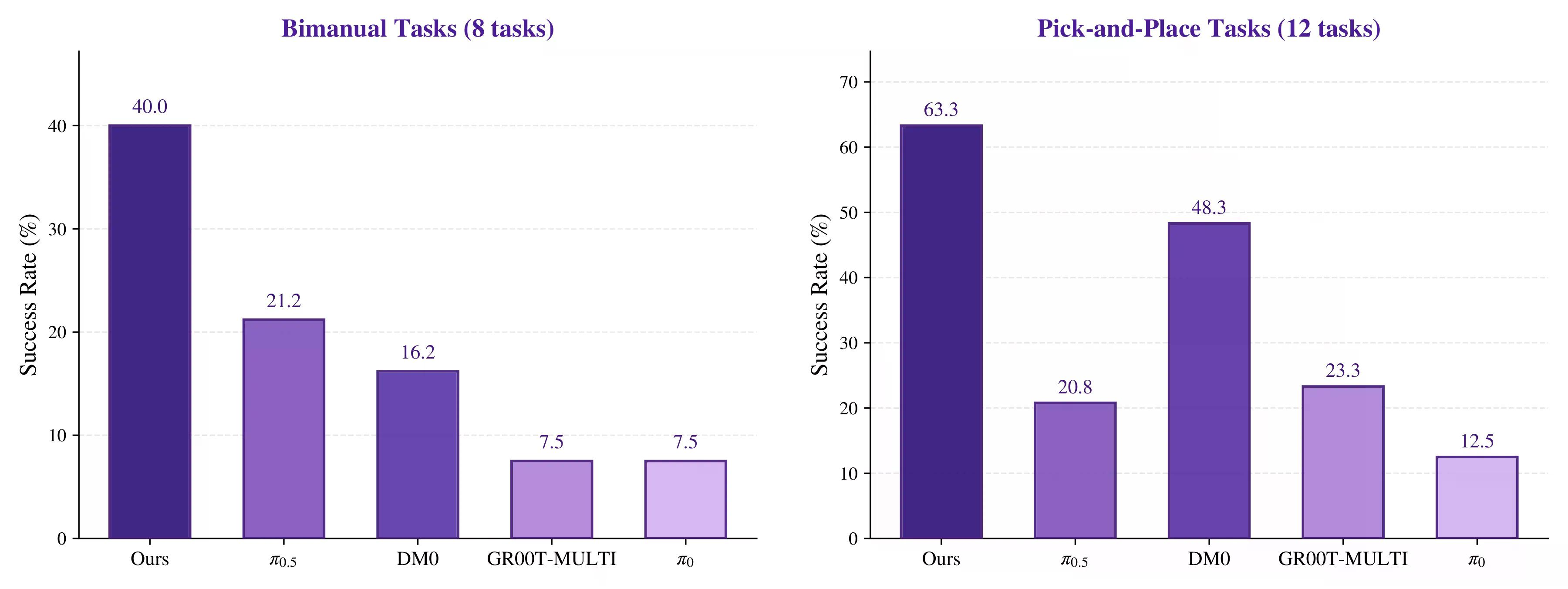
Tinutugunan ng Qwen-RobotManip ang isa sa pinakamalaking hamon sa robotic manipulation: ang iba't ibang robot ay kumakatawan sa mga aksyon sa iba't ibang paraan. Ang isang Franka arm (isang uri ng robot na may pitong axis ng paggalaw) ay gumagana sa pamamagitan ng joint angles, habang ang isang ALOHA robot (isang low-cost bimanual robot platform na malawakang ginagamit sa robotics research) ay kumakatawan sa mga aksyon sa pamamagitan ng posisyon at oryentasyon ng mga grippers nito (end-effector poses). Ang mga humanoid ay nagdaragdag ng isa pang layer ng pagiging kumplikado, na gumagamit ng whole-body coordinates.
Upang pag-ugnayin ang mga hindi magkatugmang action space na ito, ang Alibaba ay nag-synthesize ng humigit-kumulang 38,100 oras ng training data mula sa mga open-source na robot dataset at mga video ng tao—nang hindi umaasa sa proprietary data collection. Nangunguna ang modelo sa RoboChallenge Table30-v1, na nalalampasan ang mga nakaraang pamamaraan ng 20%.
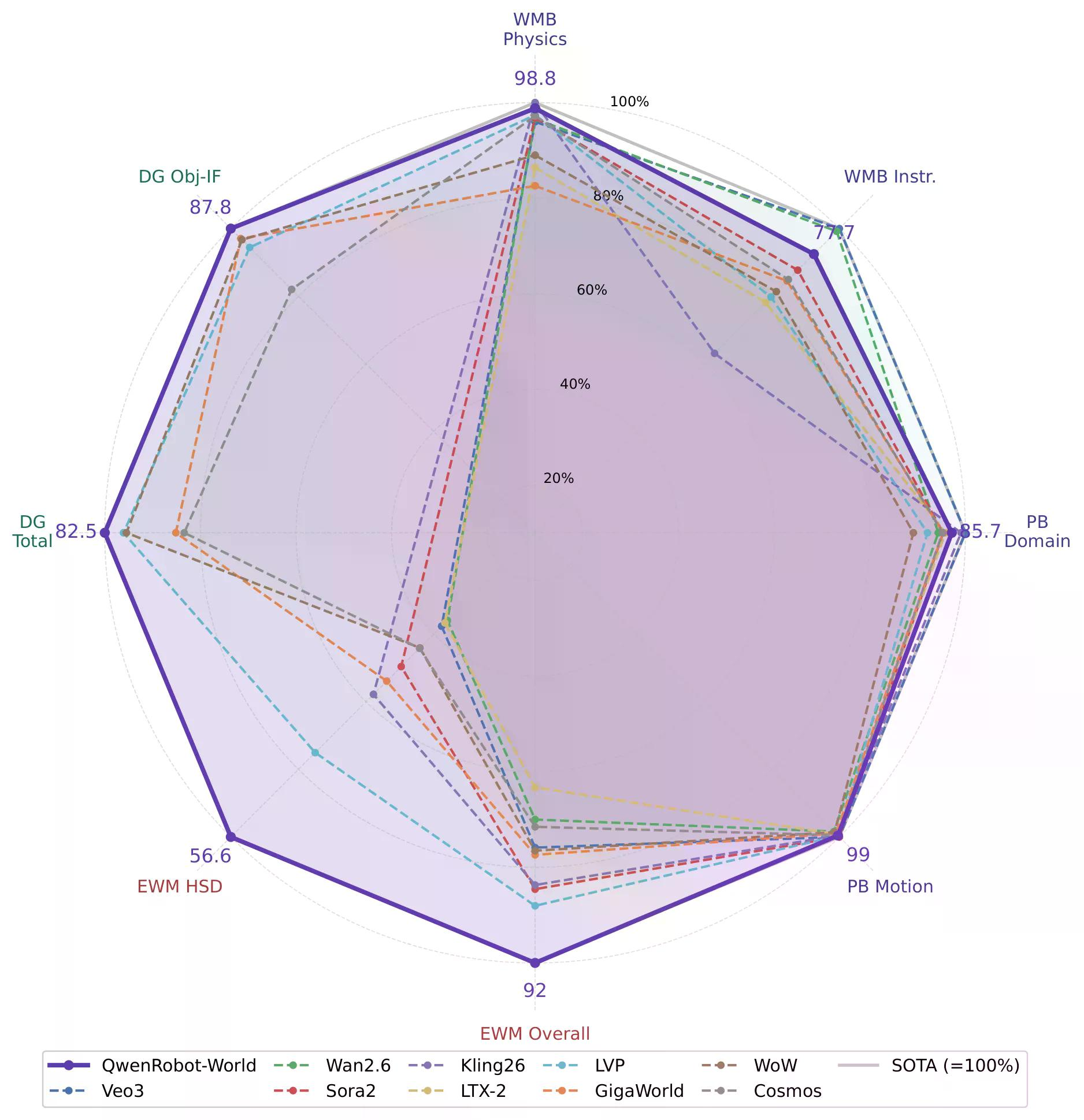
Ang Qwen-RobotWorld ang pinaka-ambisyoso: isang language-conditioned video world model na tinatrato ang natural na wika bilang isang universal action interface. Ang "Pulutin ang pulang tasa at buhusan ng tubig ang bulaklak" ay gumagana kung ang actor ay isang gripper, isang autonomous na sasakyan, o isang mobile navigation agent.
Ang Embodied World Knowledge corpus ay sumasaklaw sa 8.6 milyong video-text pairs—200 milyong frames—sa buong manipulasyon (5.9 milyong sample, 1,300+ kasanayan, 20+ morphologies), autonomous driving (Waymo, NVIDIA PhysicalAI-AD, Bench2Drive), indoor navigation (VLNVerse), at human-to-robot transfer sa 14 na robot arm.
Nangunguna ito sa EWMBench at DreamGen Bench, dalawang benchmark na sumusuri kung ang mga world models ay naghuhula at bumubuo ng makatotohanang pisikal na kapaligiran. Natalo din nito ang lahat ng open-source na modelo sa WorldModelBench at PBench, at nakakakuha ng perpektong marka sa physics adherence: mga batas ni Newton, mass conservation, fluid dynamics, gravity.
Habang ang mga Western labs (Google DeepMind, Nvidia, Figure, Physical Intelligence) ay humahabol sa magkakatulad na layunin, karamihan ay nakatuon sa navigation o manipulation, hindi sa isang pinag-isang, composable suite. Ang vertical integration ng Alibaba mula sa chips hanggang sa mga aplikasyon ay nangangahulugang kontrolado nila ang buong stack. Ang open-source na pundasyon ay nagpapakita ng pagkakaiba laban sa mga kakumpitensya na umaasa sa pribadong data ng robot.
May ilang mga maling pagkaunawa na maaaring linawin: Hindi ito mga robot kundi mga software models—mga utak, hindi katawan. Tumatakbo ang mga ito sa hardware mula sa AgileX, Franka, Universal Robots, Unitree, at iba pa.
Gayundin, sa kabila ng pagiging generative AI models para sa mga robot, hindi ito mga LLM tulad ng iyong tipikal na ChatGPT. Ang isang language model ay naghuhula ng mga token. Kailangang maunawaan ng mga modelong ito ang physics, spatial relationship, at mga kahihinatnan ng pisikal na aksyon. Sasabihin sa iyo ng isang language model na mababasag ang isang baso kung ito ay mahuhulog. Huhulaan ng Qwen-RobotWorld kung paano ito masisira—shatter pattern, fluid dynamics, secondary collisions. Nagpaplano naman ang Qwen-RobotManip ng paghawak na ganap na pumipigil sa pagkahulog.
Huwag asahang magkaroon ng sarili mong housemaid robot anumang oras sa lalong madaling panahon. Napakalaki ng agwat sa pagitan ng isang controlled demo ng isang robot na naglalagay ng prutas sa isang basket at isang robot na maaasahang gumagana sa iyong tahanan. RoboCasa365, LIBERO-Plus, RoboTwin-Clean2Rand—ito ay mga simulation benchmarks. Ang real-world deployment ay nagpapakilala ng sensor noise, actuator drift, at ang mahabang pila ng edge cases na nagpahiya sa bawat robotics effort sa kasaysayan, at kinikilala ito ng Alibaba.
Ang mga teknikal na tagumpay ay totoo, gayunpaman. Ang alignment-first approach ng RobotManip ay lumulutas sa isang tunay na bottleneck sa cross-embodiment training. Ang parameterized observation interface ng RobotNav ay isang matalinong solusyon sa problema ng context-strategy. Ang language-as-universal-action-interface ng RobotWorld ay ang tamang abstraction para sa cross-domain world modeling.
Hindi ibinunyag ng Alibaba ang pagpepresyo, mga timeline, o kung sinong mga customer ang makakakuha ng access lampas sa mga pilot program.
